
PhilaGeoHistory.org
Project Information
- Project Summary
- Data Concept Diagrams
- Tech Concept & Diagrams
- New! Pilot Grant Report
- New! Next Steps
Conference Proceedings
- Presentations / PowerPoint
- Breakout Transcripts
- Suggested Links
- Details (archived)
Advisory Committee
- Advisory Committe Forums
- Institution Survey
Useful Links
- PACSCL
- Athenaeum of Philadelphia
- Phila. Arch. & Buildings
- CML @ Penn
- CityMaps @ Phila.gov
- Boston Streets Project
- Suggested Project Links
Technical Concept and Diagrams
The Greater Philadelphia GeoHistory Network proposes gathering data from a long list of Philadelphia institutions (and other institutions that have data and resources about Philadelphia history), and using that data to build a few applications that present historical images, manuscripts, and data in geographic and temporal context. Looking past the specific data-sets and the specific institutions, there are two basic technical approaches to organizing a system such as this.
Centralized Model
The first, which is easily understood and frequently implemented for projects such as this, is a centralized model, where all the data necessary for each application is gathered and stored on a central server (or group of servers), and is accessed through one or more user interfaces.
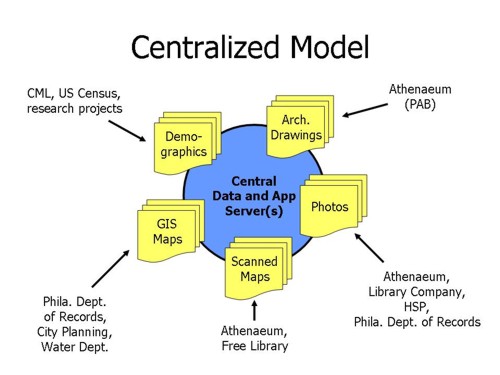
In the centralized model, data for the applications is stored in one place. The data repository system is built to support the applications (or the clearinghouse, as the case may be), and is generally not suitable to be used also for the internal needs of the various contributing institutions. For example, if the Philadelphia Department of Records were to contribute their coverage of photographs in their holdings, the central system would be unable to accomodate internal data processes (ongoing entry and scanning of old and new photos) and specialized needs (printing and tracking of photo reproduction requests).
Contributing groups would have to submit to a strictly-controlled metadata, and would have to figure out processes and policies for data refreshing, access control, and digital rights management. Already such things are difficult to agree on -- gathering data and images together on a shared system may only increase those difficulties.
In addition, a centralized system is difficult to plan and scale, as the amount of data may be overwhelmingly large, and each new institution brings additional resource demands upon the central system. This model may scale to support a large number of datasets, but it is unlikely that it would scale gracefully to support any extensive (multi-state or nationwide) collaborative projects.
Distributed Model
The second approach is a generalized hybrid of the first, and this is the model we are investigating for the GPGN project. In a distributed model, data repositories are separated conceptually and perhaps physically from each other and from the applications that utilize the disparate data sources.
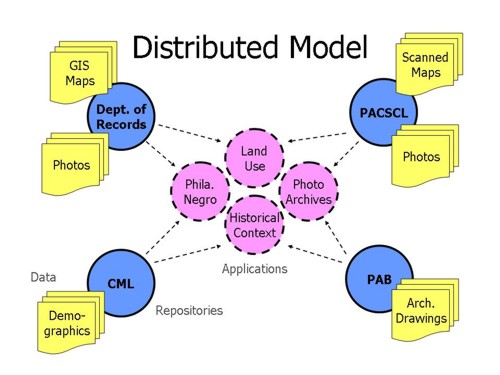
Data is stored and maintained in separate repositories (which may actually be centralized repositories, fitting the first model above). This allows metadata to be maintained in one place, in repositories that support local institutional needs (such as providing photo reproduction services) and can enforce local copyright and access restrictions. With distributed metadata and images, each institution or consortium is responsible for scaling the technology resources as necessary to support its own collections. No participant is a burden on any other participant.
The interactions between the repositories and applications are similar to the model developed by the Open Archives Initiative (OAI). Data in the various repositories can be maintained using metadata standards that are appropriate for each -- with the various schemas mapped to a minimal set of descriptors (the Dublin Core elements). Each repository maintains a special gateway that responds to queries from applications or metadata harvesters and returns metadata from its own sources.
The model described here has already been demonstrated, and is seeing increased use as OAI support grows. Thus the primary challenge in building this network is incorporating into it the necessary services and standards to effectively capture geo-temporal information -- to provide, exchange, and interpret accurate metadata for the geographic and temporal content and context of an item.